Estrategias prácticas para reducir el consumo de tokens y optimizar costos al usar Claude Code. Cubre optimización de prompts, gestión de contexto, configuración de CLAUDE.md y más para desarrolladores.
¿Por Qué Importa la Eficiencia de Tokens?
Claude Code es un poderoso asistente de codificación con IA, pero a medida que el uso escala, los costos de tokens pueden crecer exponencialmente. Los desarrolladores que trabajan en proyectos grandes o colaboran con IA durante todo el día pueden acumular gastos mensuales significativos.
Pero la eficiencia de tokens no es solo cuestión de dinero. Cuanto más limpia y enfocada está tu ventana de contexto, mayor es la calidad de las respuestas. Un contexto repleto de información irrelevante diluye el enfoque de la IA y degrada la calidad del resultado.
Esta guía cubre estrategias prácticas y probadas para reducir el uso de tokens en Claude Code.
El Principio Fundamental: Trata el Contexto como una Herramienta Quirúrgica
La clave para ahorrar tokens es dar a la IA "solo lo necesario, con precisión, en el momento adecuado." Piensa en ello como un briefing a un especialista: solo el contexto esencial, no toda tu historia.
1. Usa CLAUDE.md para Pre-registrar Instrucciones Repetitivas
Claude Code lee automáticamente un archivo CLAUDE.md en la raíz de tu proyecto. Todo lo que te encuentras repitiendo en cada sesión de chat pertenece a este archivo.
Patrón ineficiente (repetido cada sesión):
"Este proyecto usa Next.js 15, TypeScript y Tailwind CSS.
Sin punto y coma. Sangría de 2 espacios.
Siempre usa exportaciones nombradas para los componentes."
Patrón eficiente (definido una vez en CLAUDE.md):
## Estilo de Código
- Next.js 15 App Router
- TypeScript strict mode
- Tailwind CSS v4
- Sin punto y coma, sangría de 2 espacios
- Solo exportaciones nombradas
## Prohibiciones
- No console.log en código de producción
- No tipos `any`
Este simple cambio puede ahorrar cientos de tokens por conversación.
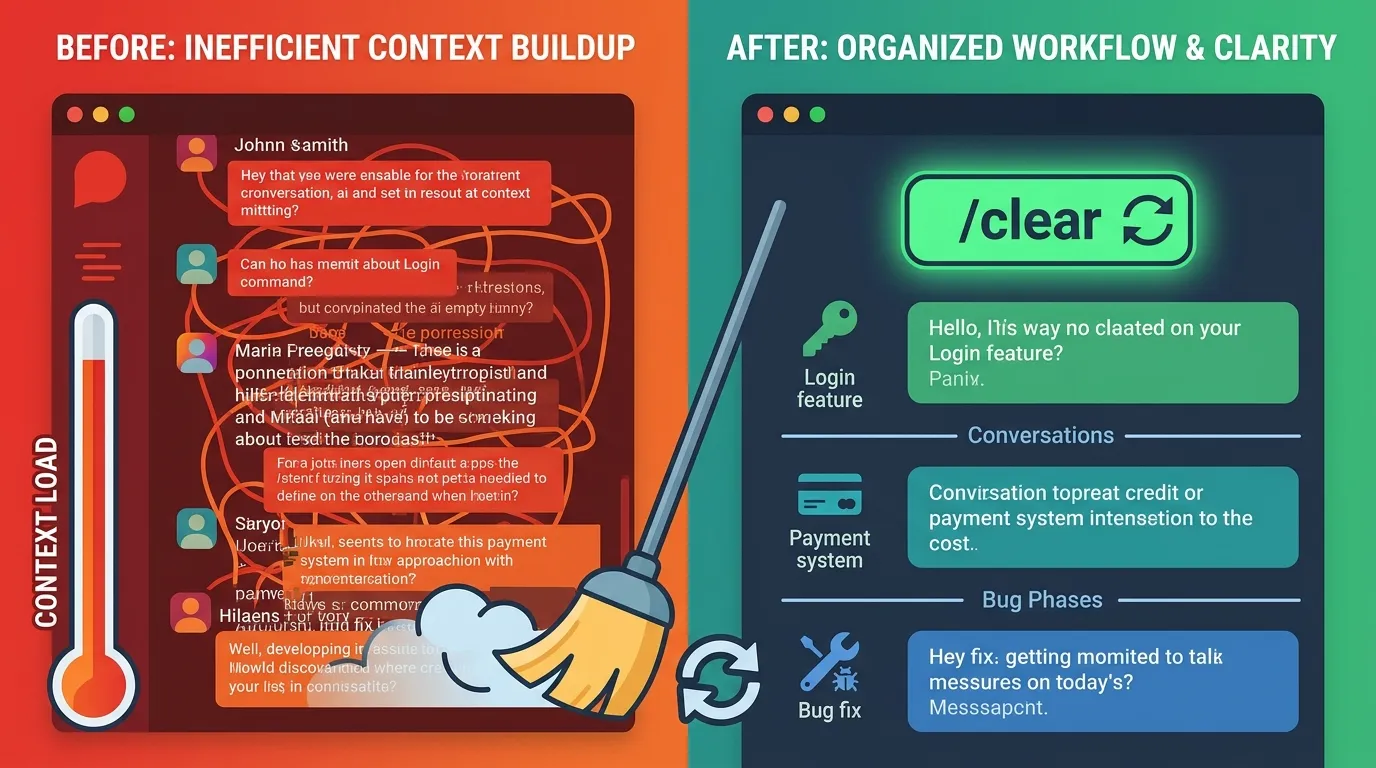
2. Usa /clear de Forma Estratégica
En Claude Code, la ventana de contexto acumula conversaciones pasadas a medida que las sesiones crecen, consumiendo tokens rápidamente. Limpia el contexto cada vez que cambies de unidad de tarea.
Por ejemplo:
- Terminar de implementar login →
/clear→ Comenzar función de pago - Corregir un bug →
/clear→ Comenzar nuevo desarrollo de función
Tratar cada tarea como una sesión independiente evita que el historial de conversación acumulado consuma silenciosamente tu presupuesto de tokens.
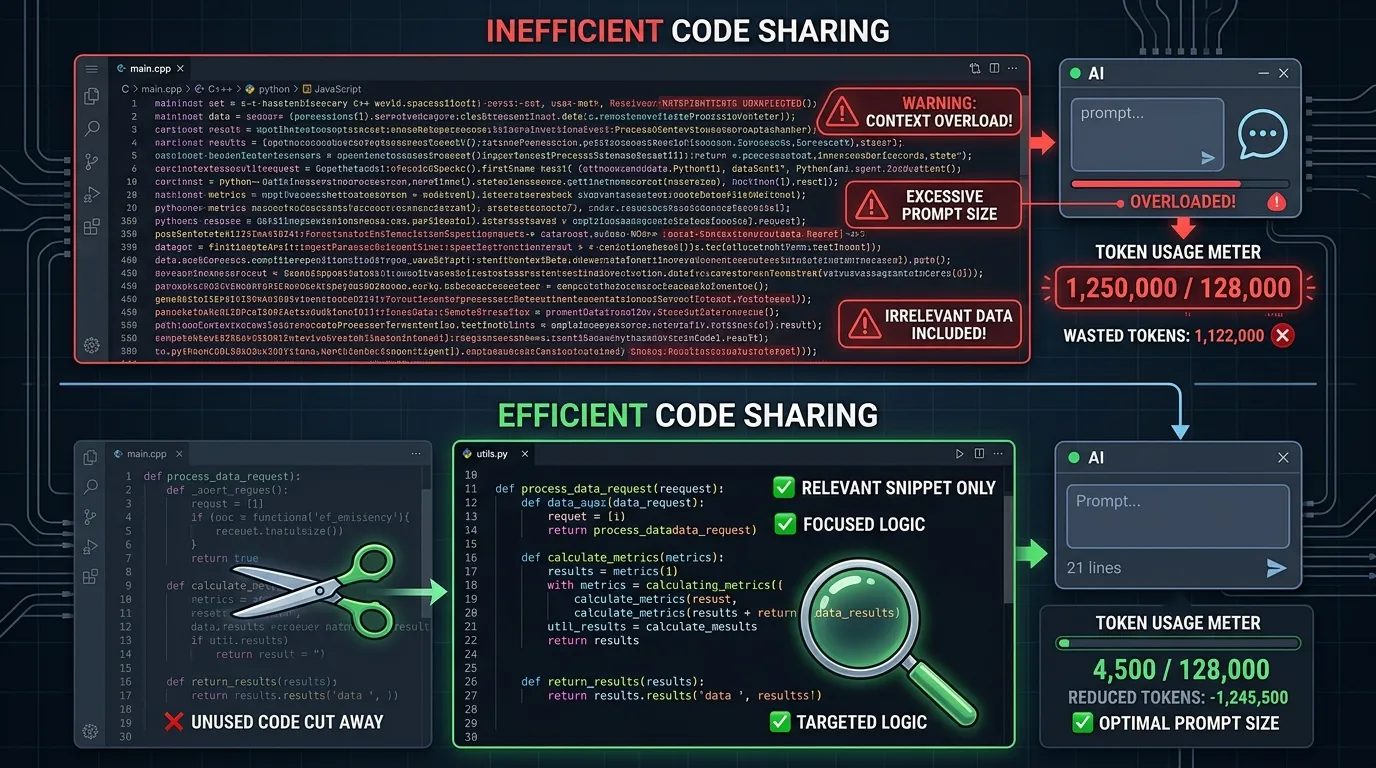
3. Comparte Solo el Código Relevante, No Archivos Completos
Al adjuntar código, copia solo la función o bloque relevante en lugar de archivos completos.
Malo:
"Aquí está todo el código. Encuentra el bug." (adjunta archivo de 500 líneas)
Bueno:
"Esta función tiene un comportamiento extraño:
[20 líneas relevantes]
Síntoma: el redirect no ocurre después del login"
4. Haz Preguntas Específicas para Reducir el Alcance
Las preguntas vagas obligan a la IA a hacer muchas suposiciones, resultando en respuestas largas. Las preguntas específicas conducen a respuestas concisas y precisas.
| Pregunta Vaga | Pregunta Específica |
|---|---|
| "Mejora este código" | "Reduce la complejidad temporal de esta función de O(n²) a O(n)" |
| "Arregla el error" | "Causa raíz de TypeError: Cannot read property 'map' of undefined" |
| "Revisa mi código" | "Revisa solo vulnerabilidades de seguridad" |
Estrategias Avanzadas: Entender los Patrones de Consumo de Tokens
5. Usa el Modo Think de Forma Selectiva
Los modos Think y ultrathink de Claude Code razonan profundamente sobre los problemas pero consumen 3–10× más tokens que el modo normal. Úsalos según estos criterios:
Cuándo el modo Think vale la pena:
- Decisiones complejas de arquitectura
- Implementaciones de algoritmos difíciles
- Análisis de causa raíz de bugs complejos
Cuándo el modo normal es suficiente:
- Ediciones simples y formateo de código
- Tareas de traducción
- Agregar funciones simples
6. Divide Tareas Grandes en Sesiones Enfocadas
Para tareas que abarcan múltiples archivos, dividir en sesiones pequeñas e independientes supera a una sesión gigante.
Por ejemplo, "Refactorizar 10 archivos" debería ser:
- ❌ Una sesión procesando todos los archivos (sobrecarga de contexto)
- ✅ Sesiones de 2–3 archivos cada una, procesadas independientemente
7. Aprovecha el Caché (Reutiliza tus Salidas)
La API de Claude soporta caché de prompts. Registrar prompts de sistema largos o documentos frecuentemente usados como contenido en caché puede reducir los costos de tokens de ese contenido hasta un 90%.
En Claude Code, CLAUDE.md efectivamente sirve este propósito. Centralizar todo el contexto compartido en CLAUDE.md te permite beneficiarte automáticamente del caché interno.
Lista de Verificación Pre-Tarea
Antes de comenzar cualquier sesión de trabajo, verifica:
- Las reglas del proyecto están definidas en
CLAUDE.md - Usaste
/clearal cambiar a una nueva tarea - Compartiendo solo bloques de código relevantes, no archivos completos
- Las preguntas están acotadas a un problema específico
- No estás usando el modo Think innecesariamente para tareas simples
Resumen de Ahorros Estimados
| Estrategia | Ahorro Esperado |
|---|---|
| Uso de CLAUDE.md | 200–500 tokens por sesión |
| Uso apropiado de /clear | 30–60% vs. sesiones largas |
| Preguntas específicas | Respuestas 40–70% más cortas |
| Minimizar modo Think | 70–90% en esas consultas |
| Compartir solo código relevante | 50–80% menos tokens de entrada |
Combinando estas estrategias puedes reducir los costos generales de IA en un 50–70%, mientras a menudo mejoras la calidad de las respuestas al mismo tiempo.

Reflexión Final
Usar asistentes de codificación con IA de forma eficiente no se trata solo de reducir costos. Cuanto más limpio está tu contexto, más se enfoca la IA en lo que importa y produce mejores resultados.
Puede sentirse incómodo al principio, pero desarrolla el hábito de usar /clear con frecuencia y mantener tu CLAUDE.md. En pocas semanas, la diferencia será evidente.
Contacto
- Email: kck0920@gmail.com
- GitHub: https://github.com/kck0920